
On TEEs for Privacy-Preserving Monitoring in AI Governance
- Gloria Z
This project was conducted as part of MIRI Technical Governance Fellowship and was authored solely by Gloria. Thank you to Aaron Scher for guidance. It does not necessarily reflect the views of the organization.
Intro
Trusted Execution Environments (TEEs) spark excitement and skepticism in the realm of AI governance verification. TEEs could be a robust way to restrict and monitor AI deployments, replacing human trust with verifiable constraints and preserving user privacy… but it is not clear if the security assumptions are acceptable.
Three scenarios in which you will wish you read this post:
- Someone interested in AI safety has jumped to the conclusion that privacy and misuse prevention are mutually exclusive. They think private AI products should be banned. They express sadness in sacrificing personal privacy, but see it as a necessary “freedom tax” to pay for safety.
- Someone in charge of security for a human extinction-level threat – ASI, for example – is overly excited about TEEs, treating them like a panacea for all trust problems. You grumble a bit about side-channel attacks and hardware vendor trust, but you struggle to provide a clear checklist of problems to solve. Most of the resources you can find are vendor-specific or outdated, so it’s hard to build a consistent mental model.
- People are poo-pooing TEEs for AI governance because of its many problems; they can’t possibly work in an international treaty scenario! You think TEEs would be amazing, but you aren’t sure how to argue for them and don’t want to seem naive about security. So you repeat the mantra “SGX is broken; you can’t trust Intel” and wonder what SGX even stands for.
This post first walks through the motivations for TEE-based approaches: they are compelling, I promise. It then builds an understanding of how TEEs work, what problems they solve (and which ones they don’t), and how commercial products map to governance scenarios. The second half of the post is less generous and more pragmatic, discussing the gaps in what can be achieved with today’s hardware. It attempts to make progress distinguishing fixable problems from fundamental limitations. TLDR: I think the biggest problem is hardware auditability.
It’s time to stop trusted handwave-ing and start trusted hardware-ing!
Motivations
Physics is more robust than trust
Any agreement to restrict the development of dangerous superintelligence is not viable without some method of verification. There are extreme incentives to covertly circumvent the agreement, especially if nations believe other parties are doing so.
Ideally, an audited party could prove that it is physically impossible for a machine to do something undesirable. As a simple example, robots can be designed with soft edges and force limits – e.g. only enough to lift 5kg or move 10cm per second – to make it unlikely to cause injuries even if safety training fails. The data throughput of network cables is similarly limited by the wire’s bandwidth, making it possible to assert that they cannot be used to exfiltrate large amounts of data, even if security protocols are violated.
In a governance scenario the dangerous behavior might be unrestricted access to dangerous models, or conducting training in general. Can we design a chip that can only run inference for specific models so that this behavior is impossible? Application-Specific Integrated Circuits (ASICs) with weights fused into the metal are theoretically possible, but would lock its applications into extremely restrictive functionality and require a bespoke manufacturing process. Frontier model architecture is far from static; frequent releases and variable load demand flexible compute. This solution is unlikely to meet industry needs. But perhaps we can get close by making it impossible to run the dangerous software undetected.
The computing industry has long been interested in deployment integrity, i.e. the assurance that software is running unaltered on a chip. Cloud computing increased interest in hardware-based security mechanisms, as another party (the hardware operator) has privileged software access on the chip. Trusted Execution Environments are intended to prove execution integrity through hardware isolation and an attestation using a unique cryptographic identity. In essence, the chip records what software runs and restricts what it can do, and the user can get verifiable information from the chip itself instead of the hardware operator. AI verification literature often highlights hardware as robust, but emphasizes its long lead times (see FlexHEGs, Secure, Governable Chips, HEMs, Hardware Taxonomy, Offline Licensing).
Privacy is a shared design goal
One concern about regulations such as access controls, age restrictions, safety filters, and content monitoring is that robust enforcement carries potential for mass surveillance. The erosion of personal privacy for the sake of – or under the guise of – AI governance should be considered one of the worst failure modes. But the framing of verifiability vs privacy is perhaps a false dichotomy.
One of the main use cases for TEEs is Confidential Computing (CC), enabling remote verification of code integrity and protecting the privacy of compute workloads. Hardware manufacturers design the chip to enable the creation of isolated areas for private workloads: sensitive data on the chip is always either encrypted or in a region with restricted access.
Perhaps misuse prevention does not require personal data collection and monitoring user chats. An alternative is to enforce it at the process level, requiring all inference runs go through the access controls, safety filters, and audit logging.
The technology is maturing just in time
Many of the aforementioned hardware-based proposals recognize that a major challenge is making the solutions practical for near-term deployment and/or retrofittable for existing hardware. Cryptographic approaches have a similar tradeoff: it’s possible to provide a cryptographic guarantee that outputs were produced by a particular model using a zero-knowledge proof, but this process slows down inference by several orders of magnitude.
While early TEEs like Intel Software Guard Extensions (SGX) and ARM TrustZone had narrow memory constraints and required purpose-built software, Confidential Virtual Machines (CVM) have emerged more recently to enable confidential computing and remote attestation for general applications. A design goal of CVMs is to be functionally similar to any other VM but offer confidentiality from the operator. Developers no longer need to write custom software interfacing with SGX or TrustZone in order to create trusted applications.
Cloud providers such as Google Cloud Platform, Azure, and Tencent offer CVMs and even migration of existing deployments. These services are often implemented using custom hardware or use AMD and Intel’s general purpose processors that are built to support Confidential Computing (CC) and remote attestations.
There are a number of proposals for verification of AI systems that incorporate CVMs to create attestable evaluations, recomputation, and deployments. Increasing support for AI workloads makes CVMs particularly promising compared to other hardware-based approaches that are further from production-readiness or require an entirely new silicon stack.
Companies are incentivized to solve these verification problems
Given AI’s enormous economic value, it is not realistic to rely on governments to compel companies to incorporate auditability into their operations, especially on a short timescale. Could we instead ask companies to build verification infrastructure because it is profitable?
A large number of AI companies are using TEEs to build privacy into their products, suggesting there is genuine market demand.
- Apple designed Private Cloud Compute using auditable open source software running in custom-built servers that emit attestations.
- Meta published their design for WhatsApp Private Processing and commissioned an audit prior to launch.
- Google created a Private AI Compute service using “Titanium Intelligence Enclaves (TIE)” added to their TPUs.
- TEE-based private AI is a primary product of Tinfoil, Privatemode AI, Confer, and Maple AI. I had no trouble finding Private AI products; these are the ones who specifically mentioned a TEE-based implementation.
- Anthropic has expressed interest in offering a similar Confidential Inference service using TEEs.
In this post, I will focus on Apple, WhatsApp, Google, and Tinfoil’s CVM-based designs published in their whitepapers and blog posts because they are already in production and follow a consistent pattern. They are not the only possible solution and will perhaps evolve significantly over time. Also, research seems to agree that a TEE-based approach to private inference is more practical than cryptographic approaches such as Fully Homomorphic Encryption.
A key design goal for these products is to be verifiably confidential. Instead of convincing users that their data won’t be collected, the company seeks to prove that they cannot see user data at all. This approach echoes our reasons for using TEEs in governance: hardware enforcement is more robust than human trust.
Verification as an auditor is actually very similar to what the user’s client software does to create a new session. The client connects to a service and verifies the TEE’s attestation, and then creates an end-to-end encrypted channel with the TEE. To make this verification meaningful, the companies also need to provide transparency logs and/or methods to audit the source code running in the TEE and used to verify attestations.
This verification design is not without challenges; its complexity makes security challenging, frontier models are too large to fit in a single TEE, and the software needs to be auditable without revealing proprietary techniques. However, these challenges also affect the viability of a commercial product, which means that AI companies are financially incentivized to help solve them. Beyond this use case, the combination of trustworthy hardware and LLMs might solve a huge number of valuable trust problems, but that’s a whole other blog post.
Theory of Change
Can we bootstrap satisfying verification processes for AI governance from commercial products with market demand, built using widely-supported hardware features and verification processes that run on every client? If the answer is yes, or we can find a way to address the limitations, verification for AI governance no longer looks like such an uphill battle. Instead of convincing trillion dollar-companies to sacrifice profit and incorporate cumbersome compliance procedures, we would be making a verification checklist on top of existing infrastructure. The outcome would be personal privacy and safe AI.
A Brief Tour of TEEs
If we want to rely on TEEs for security, it is important to clarify which problems they solve. This section serves as a “TEEs 101” to help you be more precise about which problems a TEE is designed to address. Later sections will discuss whether it adequately addresses those problems in our threat model.
I won’t go further than the basic intuition on how TEEs work; technical readers may be disappointed in the lack of detail. Please comment suggestions if you feel something is misrepresented.
Computing Basics
Technical readers may be able to skip this section. It is most helpful as a reference for terms I will use in the post.
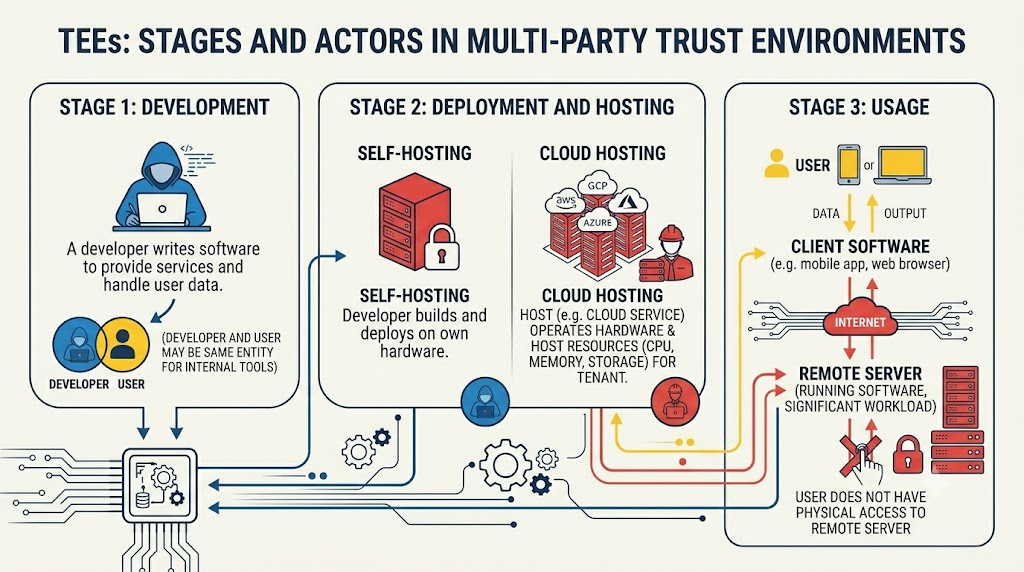
Stages and Actors
TEEs are relevant in situations where there are multiple parties who don’t trust each other. It’s helpful to enumerate the actors in each step of the process and how they interact:
- Development: a developer writes software that provides services to and handles data for users. The developer and user may be the same entity when the software is an internal tool (a personal script or a company’s internal software).
- Deployment and Hosting: The developer then builds the software. They can deploy the software on their own hardware (self-hosting) or on a separate host. Cloud computing services (e.g. AWS, GCP, Azure) are the operator of hardware and host resources (computational capacity, memory, storage space, etc.) on which the tenant runs their software.
- Usage: A user interacts with deployed software, sending it input (data and/or commands) and receiving output. Often, a user interacts with client software running on a local device (e.g. an app on their phone or a web browser on their laptop) that connects to a remote server running different software that handles a significant portion of the workload. The user doesn’t have physical access to the remote server.
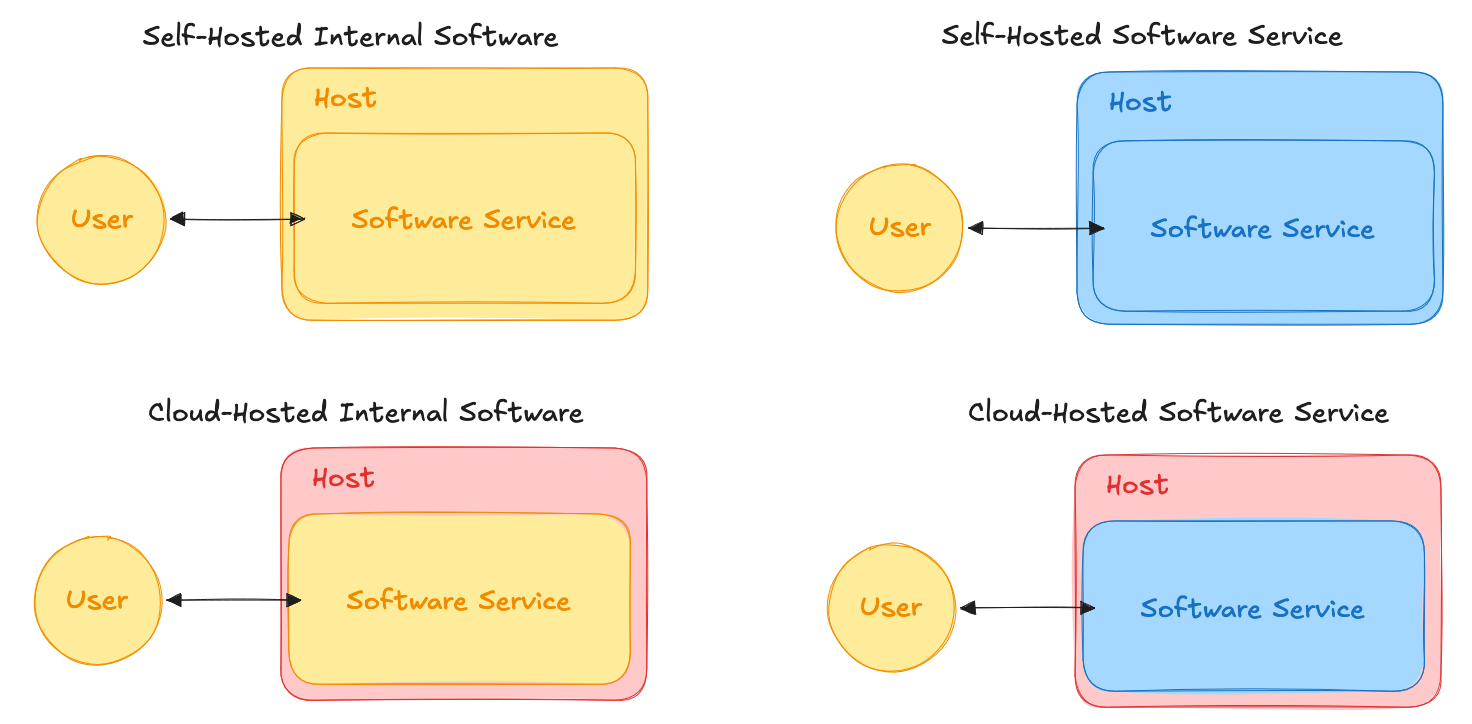
Examples:
- A researcher’s local Jupyter notebook running data analysis is Self-Hosted Internal Software
- A company's custom dashboard for sales metrics hosted on AWS is Cloud-Hosted Internal Software
- A company that runs their e-commerce site from a server room is running a Self-Hosted Software Service (“self” refers to the developer, not the user who purchases items through the site)
- A mobile banking app is commonly a Cloud-Hosted Software Service
Model Inference
In the scenarios we are most interested in, the user is neither the developer nor the host, which means these roles have mutual distrust and privacy requirements. The user interacts with a separate piece of software (e.g. coding assistant, chat app, robot) that connects to servers to handle authentication, scheduling requests, retrieval of relevant data, tool use, and other components in addition to inference. The end-to-end process may involve several hops through multiple servers, all of which can affect the user’s privacy (or lack thereof).
In this post, I’ll use inference engine to mean software that combines the model and user inputs to generate outputs, like vLLM or llama.cpp. The inference pipeline is the end-to-end code path that takes a user's input (i.e. prompt) into a model output. In addition to generation using the model, it may include filtering inputs/outputs, checking signatures, logging, etc. A deployment is one running instance of the pipeline on specific hardware.
CPU Basics
Some basic anatomy that is relevant to TEEs: CPU processor cores are the compute units, each consisting of a control unit that sequences instructions, a logic unit that executes them, and a small memory “scratchpad” made of registers. An instruction may be something like “take the values in register 1 and register 2, pass them through the ADD logical unit, and write the output back to register 1.” There is a hierarchy of on-die (on the same silicon chip) memory caches, but most memory is off-die on a separate DRAM chip connected via a physical bus. The communication with that chip is managed by the on-die memory controller.
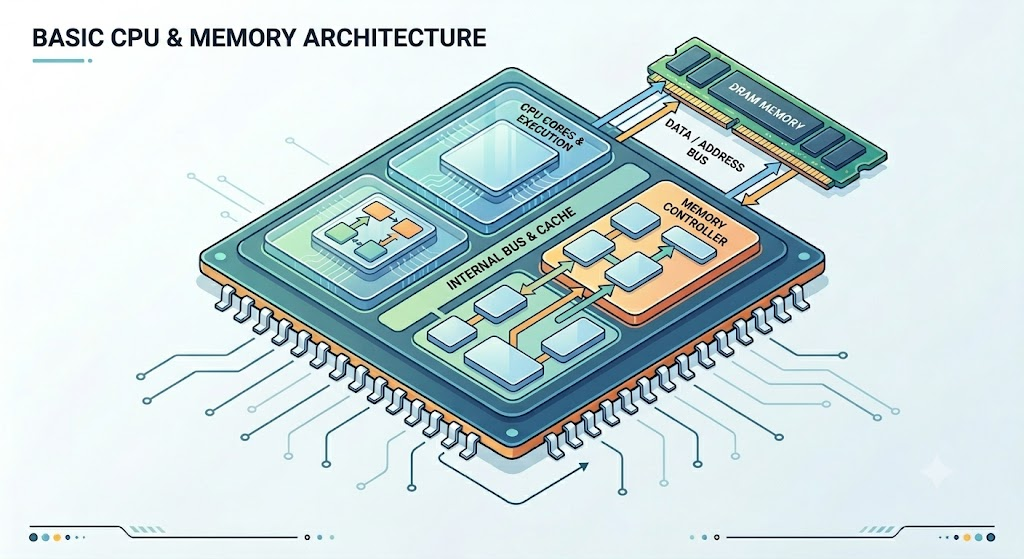
A GPU has a similar architecture: compute cores and memory (a cache hierarchy, memory controller, and DRAM). Unlike CPUs, which are designed to execute arbitrary code with diverse and unpredictable instructions, GPUs are designed for fast execution of the same few operations on many data elements at a time.
The hardware enforces privilege levels or modes that define which operations are permitted and what areas of memory can be accessed. Kernel mode has higher privileges than user mode.
When a chip powers on, here is the sequence of steps that execute before an application such as vLLM can run. You don’t need to dwell too much on the specifics, but have a basic idea of the hierarchy and layers of software that sit between an application and the bare metal.
- ROM: The CPU's on-die read-only memory runs unconditionally at power-on. It can do things like load the next stage, verify a signature, and then hand control to that code.
- Firmware: (e.g. UEFI) initializes DRAM, enumerates PCIe devices, and loads CPU microcode (the firmware layer that translates instructions to silicon micro-operations). It loads the bootloader and, for a Secure Boot, requires a valid signature in order to run it.
- Bootloader: (e.g. GRUB or systemd-boot) finds the OS kernel, loads it into memory, and jumps to it.
- Kernel: The OS kernel (e.g. XNU or Linux kernel) runs at the highest CPU privilege level, owns the page tables, and manages all hardware access for user processes running above it.
- Hypervisor: In virtualized environments, the hypervisor creates virtual machines (VMs) that appear like regular machines, each with their own guest OS. In a standard setup, the hypervisor manages – and can thus read – guest memory.
- Application: User code can be loaded and executed, at the lowest privilege mode.
TEE Hardware Features
TEEs extend this basic architecture with a few specific hardware features. Together, they form the trust anchor everything else builds on.
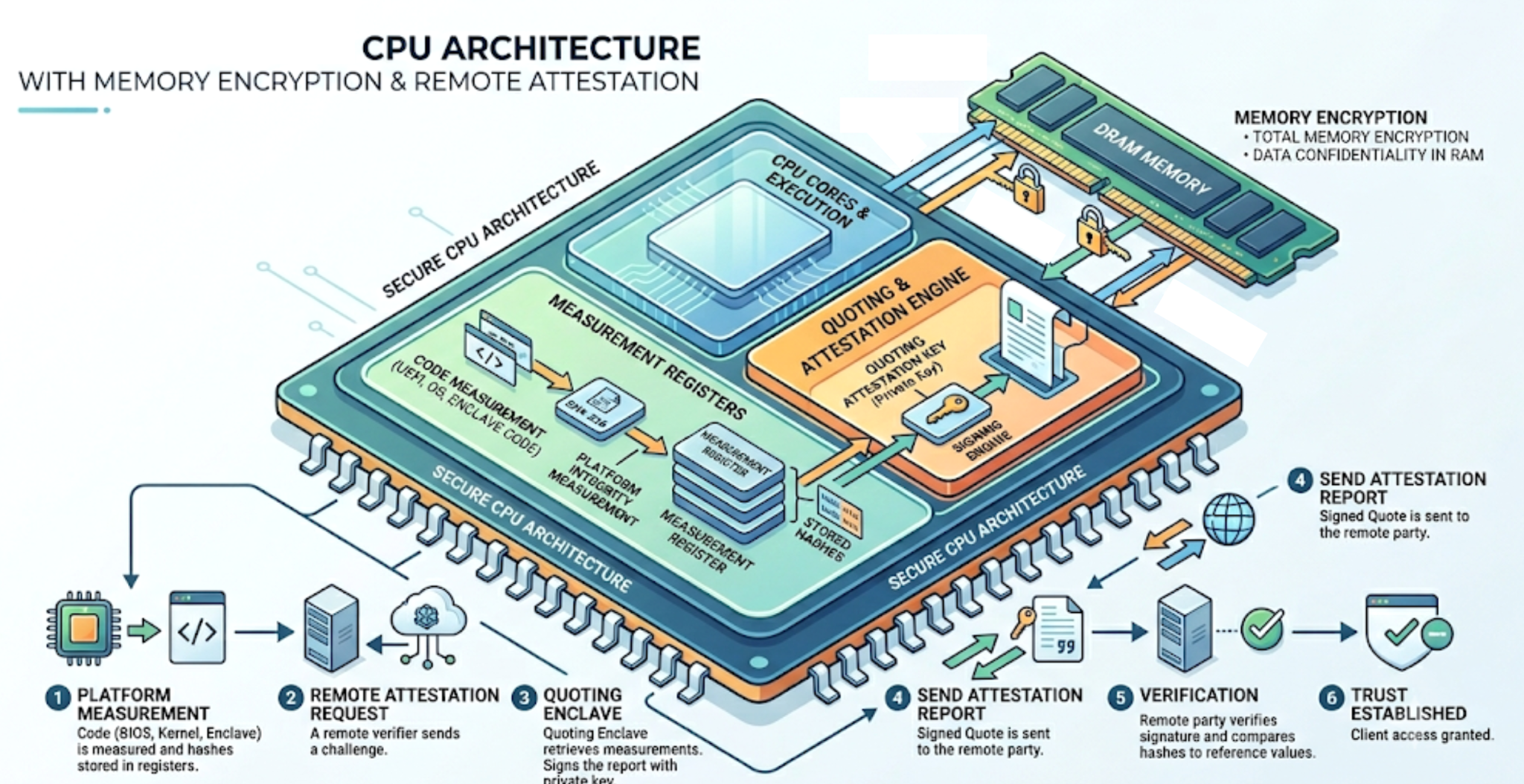
- Memory isolation: One way of picturing a TEE is an isolated region in which sensitive programs run. The hardware can restrict access to certain areas of memory. For example, ARM TrustZone partitions memory into two “worlds” and prevents access to the “secure world” physically.
- Memory encryption: A common approach is to use a normal memory layout but encrypt before transferring data from the core to DRAM. At boot, the chip is configured to encrypt memory using a hardware-generated encryption key. The hypervisor still brokers access to memory, disk, devices, etc, but only sees opaque ciphertext. The encryption keys live in protected hardware registers, inaccessible to software running at any privilege level. Attempts to snoop the data in memory are thwarted by encryption, but access patterns are still visible.
- Measurements: A measurement is the hardware's reading of some component of the state, such as the initial memory contents at launch or the program that was loaded for execution. During a measured boot, each hashed boot stage is used to extend the measurement in a measurement register (PCR, MRENCLAVE, RTMR) which serves as a tamper-evident record of what has loaded on the chip.
- Hardware cryptographic identity: The hardware has a unique secret key fused onto the chip. This key is then used to certify attestation keys that correspond uniquely to the hardware. An end user verifies signatures from attestation keys and the accompanying certificate chain ultimately rooted in the hardware vendor’s root CA. Without the certificate chain, all we know is that some key signed the hash.
- Attestations: A report contains the hardware’s measurement and details about the hardware and firmware that recorded the measurement. This report can be sent to a remote verifier as a quote, signed by the hardware-provisioned attestation key, to prove that the TEE has a specific launch state. The signature comes from a key certified by the hardware vendor as uniquely identifying that chip.
Encrypted memory and code measurement are combined to create isolated enclaves whose privacy and integrity can be verified remotely. Intel SGX does this at the process level: a single application runs in a protected region. AMD Secure Encrypted Virtualization - Secure Nested Paging (SEV-SNP) and Intel Trust Domain Extensions (TDX) create Confidential Virtual Machines (CVMs) called SEV guests and Trust Domains (TD) respectively, which provide a guest OS.
Fair warning before moving on: this description is deliberately simple and tidy in order to make it easier to organize TEE concepts without an entire CPU crash course. A lot of the problems live in the parts I smoothed over: firmware in cores implement speculative fetching, reordering, caching, etc. that are critical for performance but make its behavior harder to reason about. There are multiple keys and components involved in encryption and attestation; it isn’t just one key fused onto a chip. These details will come up in later sections describing security issues and limitations.
Does it support AI workloads?
AI workloads are uniquely demanding. Frontier model inference typically requires the memory and/or computational resources of multiple external devices (i.e. GPUs). The GPU has its own cores and memory that isn’t managed by the CPU’s memory controller.
Here, economic incentives help us out again: cloud-hosted models fit squarely into the category of sensitive workloads that require privacy from the operator or other tenants of the cloud hosting service. GPU Confidential Computing support is less mature than CPUs, but is seeing traction.
Google and Apple both mentioned GPU and TPU enclave support in their Private AI designs. NVIDIA's Confidential Computing mode on H100, apparently intended for Privacy in AI, has its own attestation chain (per-chip identity that generates an attestation key, firmware measured by on-die root of trust) which should be fetched from the CVM boot program. The CPU and GPU can establish encrypted communication so that any observers of the physical connection see only ciphertext. The GPU attestation can be bundled with the CVM's own attestation when a client requests it.
Verification Problem Hierarchy
Our goal is to bootstrap a verifiable data center from a verifiably confidential inference service. I’ve found that it’s helpful to build the problem requirements up from a basic CVM use case so we can see which problems are shared vs new, and which are solved by a TEE vs require further work.
Verifiably Confidential Computing
Verifiably Confidential Computing is the classic use case for CVMs. A CVM provides an environment just like any other VM - a kernel and userspace with full flexibility - with particular properties of isolation and confidentiality. The user feels confident in the integrity of what was booted because the hardware attests to the program by hash, and in the privacy of their data because of the hardware isolation and memory encryption features.
The main requirement of this problem is privacy: specifically, that the operator cannot see the user’s code or data. The TEE only provides privacy within the chip; data can still be sent to other devices through unprotected channels. For example, if the code is sending all the data to another server (intentionally or unintentionally), the software has completely destroyed confidentiality without breaking the hardware’s encryption scheme.
As such, in order to believe the operator cannot see their data, in addition to trust in the enclave’s isolation robustness, the user must have assurances of deployment integrity, i.e. that the code is running unaltered. In other words, you can’t have privacy without integrity.
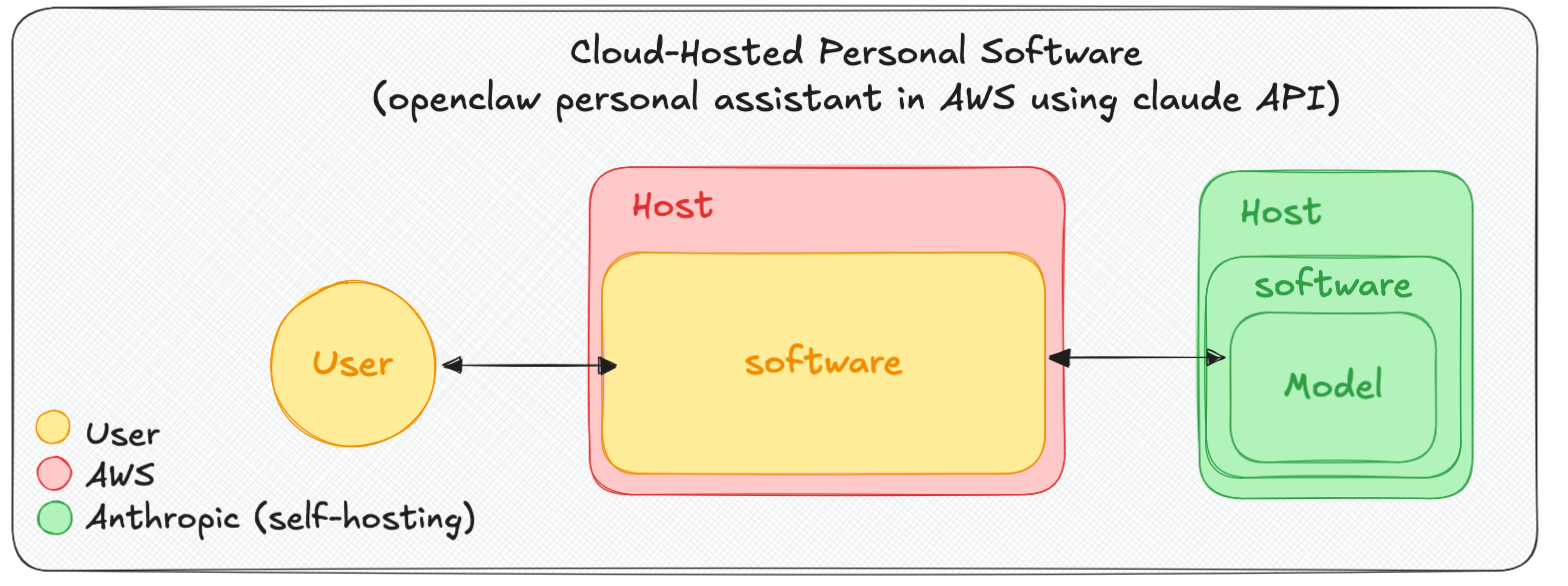
Example Verifiable Confidential Computing: A user is concerned about the security of running an OpenClaw bot on their own device, so they decide to host it on AWS. They want privacy, so they choose an AWS Nitro Enclave (a TEE) and verify via the hardware-provided attestation that the deployment uses their exact Docker image. The bot’s “brain” is an LLM that uses the Claude API: the software opens a connection to a server, sends the bot’s prompts, and receives responses. The user’s data is not private from Anthropic; the Claude API lives outside of the TEE boundary. There isn’t necessarily a bug or vulnerability here in this scenario, but it highlights the role the software plays in enforcing a desired policy.
Verifiably Confidential Service
In the previous verification problem, the host is trying to prove to the remote tenant that their code is running unaltered in a confidential enclave. In contrast, in this problem, the user is not the code’s developer or builder.
Verifying the integrity of trusted (i.e. written/built by the User) software deployed in an untrusted environment is close but not identical to verifying untrusted software deployed in an untrusted environment. The user didn’t write the code. Even if the TEE guarantees deployment integrity, the user has to determine if that means guaranteed privacy or guaranteed retention of all of their personal data.
Verification of software correctness and policy adherence usually involves reviewing the source code and/or testing the deployment image. More generally, every aspect of the deployment should originate from a publicly auditable artifact so that the user can verify its adherence to being privacy-preserving.
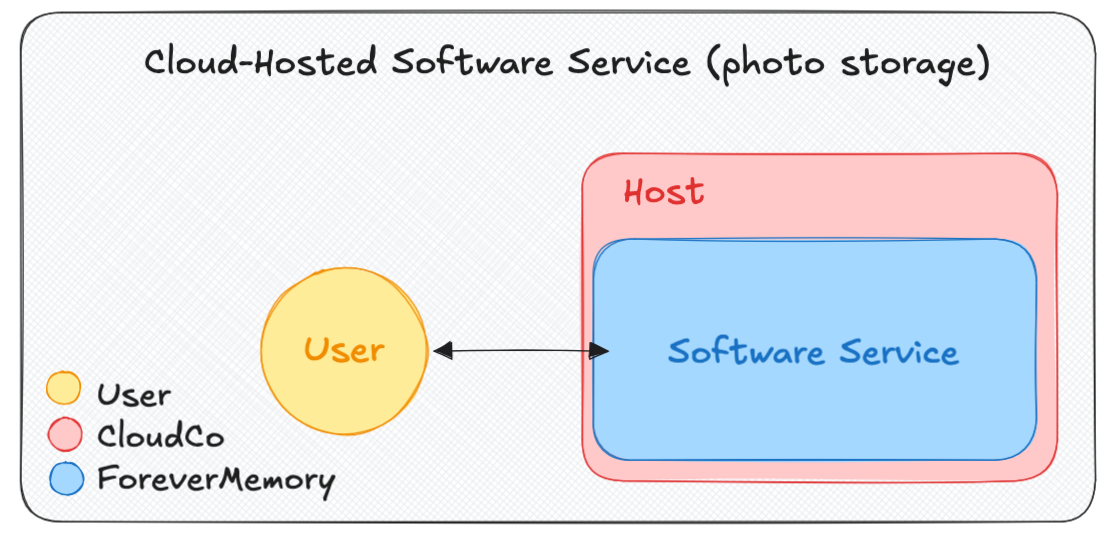
Example Verifiable Confidential Service: A user stores their photos using ForeverMemory, a storage app with file encryption and sharing, which hosts their service on CloudCo in a CVM. The CVM provides attestations showing that their software is running unaltered in a hardware-protected enclave. If the user feels satisfied that ForeverMemory receives all of their data encrypted, they might not worry about CloudCo seeing their data.
Verifiably Confidential Inference
Verifiably Confidential Inference has the same requirements as a Verifiably Confidential Service – the service in this case is an inference engine – but has a few key practical challenges that are relevant to deployment feasibility.
Sometimes, inference involves delegating computations to another device (usually multiple GPUs in the case of frontier AI models), and the TEE boundary needs to be adequately extended to those devices.
The model provider may also be releasing sensitive data (the model) into the TEE, and needs reassurance that the operator cannot see their data. They are also interested in privacy from the user - i.e. the user shouldn’t be able to learn model weights from their prompts. This requirement is largely met by a similar verification of the deployment integrity and review of the software which they control.
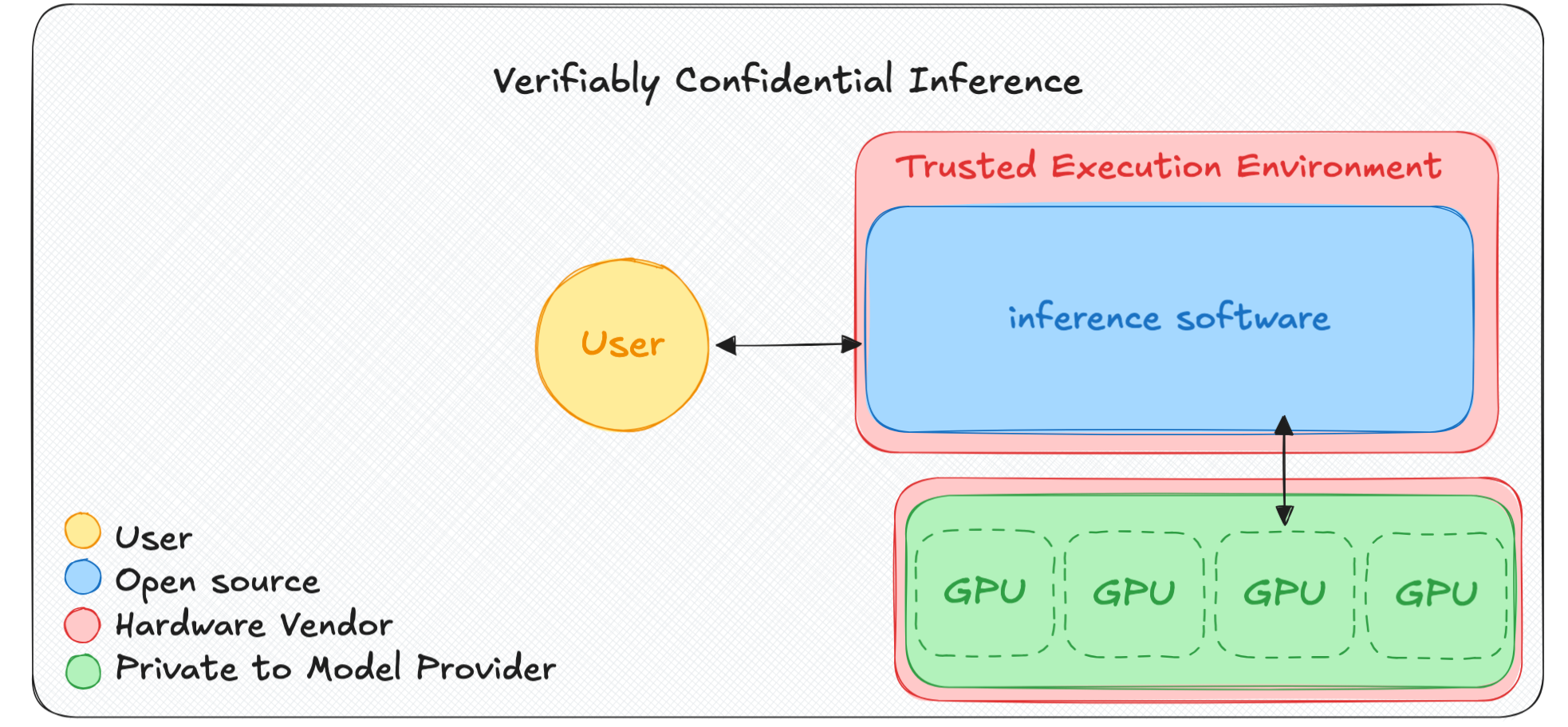
A third party who is not the user, developer, model provider, or operator can also use the same process as the user (request a remote attestation and review the deployed code) to verify confidentiality without seeing the user’s data. A company could theoretically give a treaty verification auditor the ability to request remote attestations from all of their deployments. The auditor doesn’t necessarily need to be a governing body. In fact, this auditing method could be used to verify that the government isn’t misusing AI for surveillance.
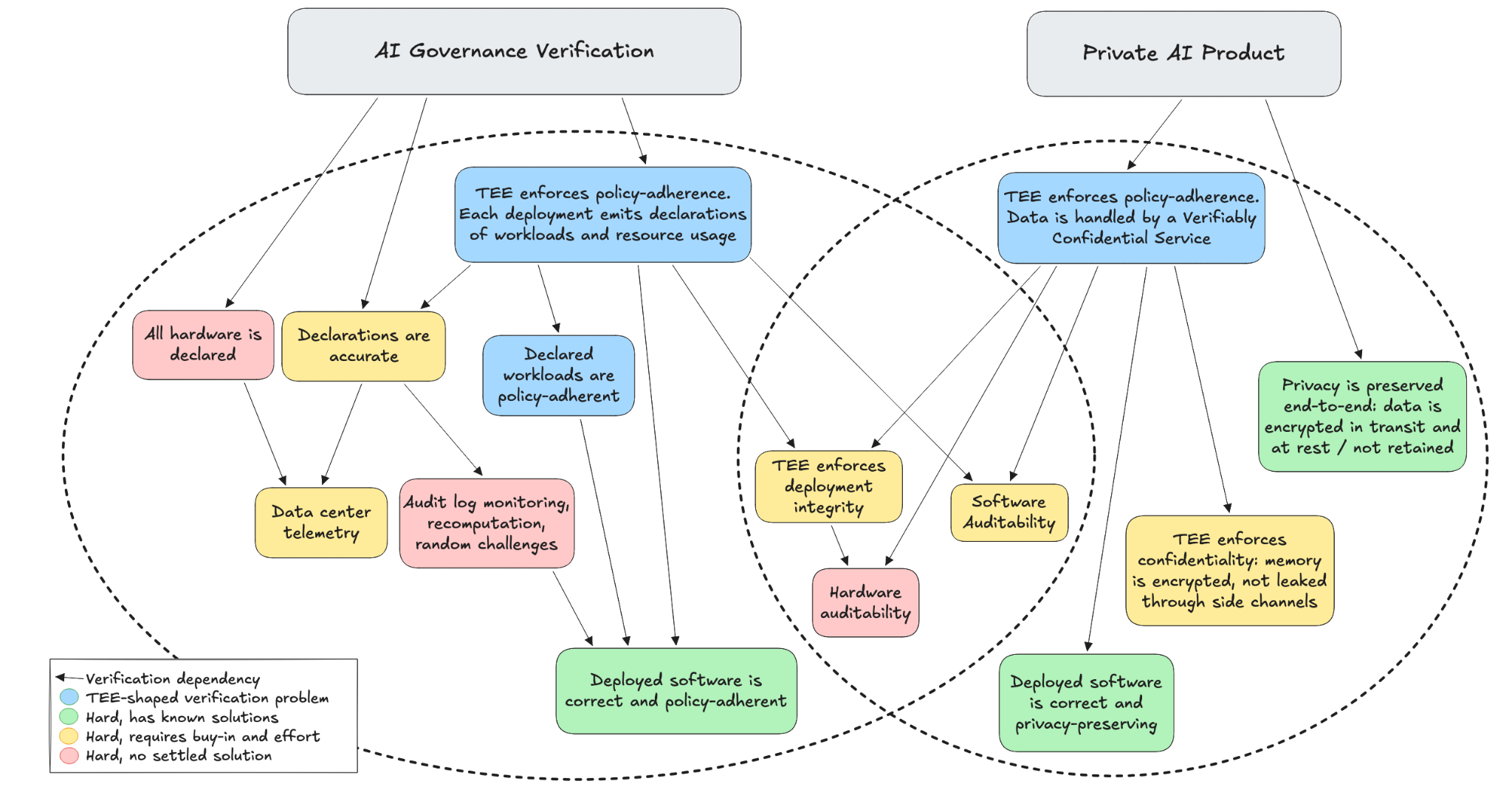
Verifiable AI Governance
Verification for international AI governance is often compared to verification for nuclear non-proliferation agreements to emphasize its high stakes and need for international cooperation. Hot take: AI governance is significantly harder. The development of a “dangerous model” doesn’t necessarily require rare, detectable radioactive materials, and the model itself is essentially just a collection of numbers that can be trivially duplicated or transported across borders.
Perhaps the AI equivalent of fissile materials is chips (GPUs, TPUs, accelerators) or, more generally, computational resources. A common framework for verification starts with the requirement that AI companies declare AI-related workloads, similar to declarations of nuclear facilities and materials to the International Atomic Energy Agency. The verification problem then decomposes into verification that those declarations are accurate, policy-adherent, and complete.
For example, a company might declare that their data center with 10,000 GPUs solely runs inference for a particular set of models. They provide a log of workload declarations. A workload declaration may state that, at some timestamp, a server produced outputs Y with model M with this data X, committing and obfuscating the raw data using hashes.
- Accuracy: It must be possible to confirm the declaration’s representation isn’t fraudulent, i.e. overstating a workload’s computational resources or specifying a different model.
- Policy-Adherence: Workloads need to contain sufficient information so that we can verify that it is using that specific model (i.e. the one that was deemed safe or weak enough) or enforcing access controls and safeguards.
- Completeness: We want an upper bound on the amount of computational resources that are not accounted for in the declarations. Completeness includes both the possibility of untracked chips as well as known GPUs concealing a portion of its workloads.
Is governance-related verification easier if companies serve Verifiably Confidential Inference?
It seems like a relatively small step to go from verifying that software is private to verifying that the inference pipeline is policy-adherent in a different way. For example, we can add a policy of audit logging to the software: it must log metadata for each inference run, record the computational resources used, and append a workload summary to a tamper-evident transparency log at regular intervals.
Policy can include safeguards and access controls: All inputs must pass through safety classifiers and scanners looking for patterns of misbehavior. Flagged user data go to another private inference system that makes moderation decisions; it has its own policies as well, including privacy. Access control can also be enforced in a privacy-preserving way, i.e. gating on a signature from an authorization module or zero-knowledge proof-of-age from a third party identity checker. Neither the service provider nor an auditor needs to pair identification with user data in order to verify that access control protocols are in place.
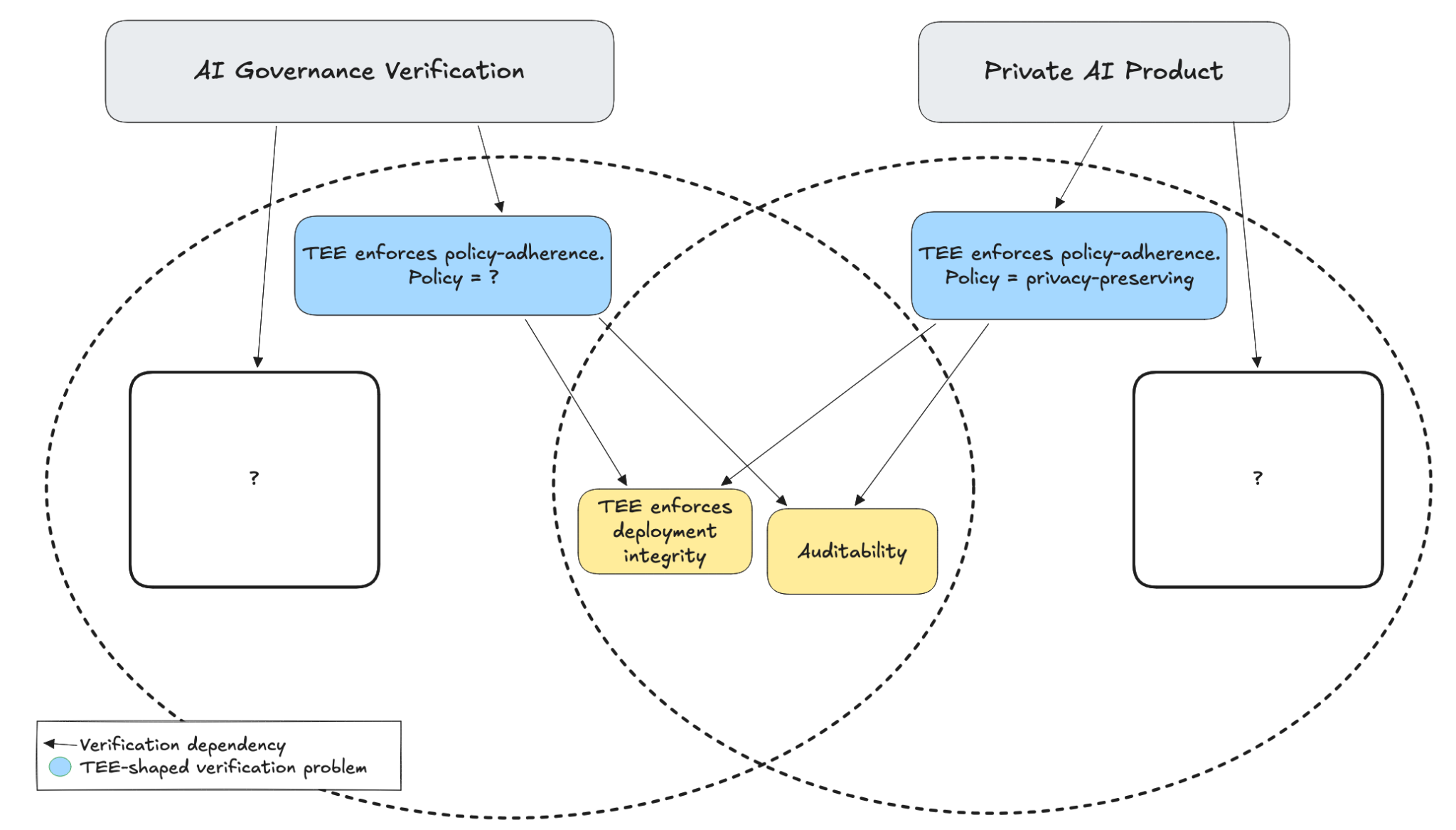
If the TEE’s security properties hold and we conduct a thorough review of the code it runs, perhaps we can verify accuracy and policy-adherence in the same process we used to verify that the service is privacy-preserving. If we require every chip in the data center to attest to this code running, perhaps we have completeness within that facility. Slap some GPS trackers on all GPUs and Bob’s your uncle – are we done?
TEE Gotchas
Let’s first assume that we are done (we’re not) and we just need to verify and enforce policy-adherence through the TEE. Let’s flesh out its details and enumerate the problems we might run into. This section draws heavily on material published by companies about their designs and/or design goals (Tinfoil, Apple, Anthropic, and Meta).
This section will also be useful to those who are overly optimistic about TEEs or wonder what could go wrong. To recap our verification checklist:
We rely on deployment integrity through the TEE, a solid assessment of correctness and policy-adherence of the deployed software, and a level of auditability that minimizes trust in any given party.
Deployment Integrity
In our CVM-based solution to verification, deployment integrity rests on our assumption that the hardware correctly reports its state. The report must be complete and up-to-date.
Trusted Computing Base Credibility
The deployment integrity depends on a stack of hardware, firmware, and other security-critical software called a Trusted Computing Base (TCB). It is the foundation of security in our use case and thus must be credible. Reliance on a TCB is not new – key generation and other cryptographic operations require a correct implementation and good entropy from a Trusted Platform Module (TPM) – but we’ll spend some time discussing the important problems here.
Ensuring deployment integrity is not only about manufacturing the chip and attestation logic correctly. TEEs’ complexity leads to a broad attack surface; documented attacks are numerous and known to break the privacy properties of CVM-based private inference. A high volume of vulnerabilities is not necessarily indicative of a fundamentally broken approach. Complex systems inevitably have bugs; security research is slow for closed-source designs and hardware. Examining the source of vulnerabilities can help us build our checklist of what must be audited (and what must thus be auditable).
Physical attacks: The original threat model for trusted hardware is focused on software attack vectors: an untrusted party may run privileged software on this chip to access private memory or tamper with code execution. A primary aim is to keep out system administrators who have root access or control the OS, but a rogue data center employee may extract information through physical access to the chip. Security cameras and locked cages help deter such physical attacks in normal cases. But key extraction through bus interposition and predictable encryption patterns is relatively low-hanging fruit in an international treaty scenario.
Side-channel attacks: Unfortunately, not all software threats are addressed either. Side-channel attacks like Spectre and Foreshadow exploit CPU microarchitecture behaviors such as speculative execution to “trick” it into making the protected memory readable by another piece of software running on the same machine. PlunderVolt uses an interface for controlling CPU voltage and frequency (normally exposed for performance fine-tuning) to cause computational errors that lead to key leakage. These vulnerabilities could be patched, but illustrate the broad attack surface beyond a breakage of the memory encryption scheme. Some implementation quirks are also performance optimizations that would be costly to forfeit for security.
Metadata leaks: Correlation between known requests’ timing and traffic volume on the machine can deanonymize users or leak other sensitive information – metadata is another side channel. Privacy leakage through metadata is an important consideration in the verification design. For example, performance counters may be useful for verification to compare the declared workloads against measured resource usage of the chip, but the CounterSEVeillance attacks show they can reveal secrets through value-dependent execution of operations.
In the international treaty verification threat model, all of these issues are in scope. The auditees have physical access to the chips. Vendor collusion and secret backdoors may not be so far-fetched if national security or trillions of dollars are at stake. It is likely unacceptable to rely exclusively on hardware vendors headquartered in the same country. Given the opacity of hardware manufacturing and firmware, many claims of security are not even possible to verify. See the later section on auditability.
Measurement Completeness
After establishing the hardware trust anchor, the launch measurement needs to restrict the behavior of the software as much as possible. The primary concern is measurement completeness: every component that influences inference behavior must be covered by the launch measurement. It’s also important to consider dangers from modification or composition after the measurement.
Trail of Bits’ audit of the WhatsApp design heavily emphasizes measurement incompleteness as a source of vulnerabilities. Feature flags, environment variables, and invocation arguments that are consequential to the important inference properties must be part of the measurement. Potential coverage issues are numerous and are perhaps the most likely failure mode; they allow an adversary to completely undermine deployment integrity without breaking a hash function.
Another completeness concern is that launch state measurements don't necessarily translate to runtime conditions. The mere presence of a program does not guarantee that it will be run. After boot, the CVM has a running kernel that, if compromised, could modify binaries, swap shared libraries, or alter configuration files. One example of extending the launch measurement to runtime state is the Tinfoil CVMImage including a configuration file committed in the command line and a first stage boot program in the initrd. The boot program runs first and effectively extends the launch measurement to cover runtime conditions by enforcing the configuration file’s requirements, fetching attestations from attached devices such as GPUs (entirely different devices and thus not inside the CVM), and appending the outcomes to the report signed by the hardware.
Hashing schemes for model integrity can fall into a similar trap. If we underspecify how to sequence the values (e.g. in an effort to obfuscate model architecture) or check too early in the loading process (e.g. to account for quantization) we might inadvertently fail to commit to all relevant properties of the data. A bad hashing scheme would make it possible to create two models with significantly different properties that share a hash, without breaking the hash function itself.
As with any security problem, verification is a live process; results can be invalidated with new information. Of course, reports should include a nonce from the requestor to avoid replay attacks. The report also needs to include versions of the TCB and the auditor must have an up-to-date understanding of the security of those versions. After firmware vulnerabilities are discovered and patched, deployments running previous versions should be considered insecure immediately.
Software Correctness
Deployment Integrity is about ensuring a specific piece of software is running inside the TEE, but does not say anything about whether the code is policy-adherent. Policy deviations can come from simple bugs in the application, a kernel vulnerability that disables integrity checks, and user mistakes in operation.
This problem isn’t unique to AI governance or verification – system simplification, comprehensive testing, supply chain hardening, and typical security principles all apply here – though its high stakes demand strong security assumptions. Companies’ Verifiably Private Inference designs often mention:
- Minimal base image: Reliance on kernel features means that a kernel exploit can disable them at runtime. A purpose-built kernel image contains only the kernel, the init system, and the application. It does not need additional features, especially ones that can alter state: package managers, shell, SSH, Bluetooth drivers. An ideal situation wouldn’t even have a kernel but we need a GPU driver to run inference.
- Properly gating on verification success: A deployment must not load model weights or accept user data before the attestation report has been verified and accepted by the relevant parties. It would have a window during which sensitive data is present in the CVM but no external party has confirmed the CVM's integrity. The design should include a key management system and ensure that decryption keys for model weights are released only after the model provider verifies the attestation, and that user connections are accepted only after the client has verified the report.
- Non-targetability: It shouldn’t be possible for an adversary who controls request routing or infrastructure to single out a specific user and route their queries to a compromised node. Relay nodes and metadata obfuscation may help make it more difficult to target users. Publishing releases to a public transparency log is one way to prevent a one-off backdoored deployment for a specific user.
- Supply chain and build attacks: Dependencies introduce complexity and can create a supply chain attack surface. A pinned, reproducible build from source — where every dependency is specified by hash, fetched from auditable sources, and compiled deterministically — narrows the supply chain to artifacts an auditor can inspect.
Auditability
Even a simple Verifiably Confidential Inference product has a long list of things to audit and monitor: the source code for the CVM image, the expected hashes to be measured by the hardware, a fresh attestation, certificates for the signing and encryption keys, etc.
Ideally, every item on the verification checklist can be verified by anyone using publicly available information. Without auditability, this hardware-based solution has not replaced trust assumptions, only shifted trust to the hardware vendors.
Software Build Provenance
Let’s start with the software. A hash of the loaded software and open source code don’t actually mean much if an auditor cannot verify the build provenance, i.e. that this binary was produced from the source code.
Supply-chain Levels for Software Artifacts (SLSA) is a framework for build integrity and security. From an auditability standpoint, ideally, the build is fully reproducible, meaning anyone can build an identical binary from the source code with all inputs — toolchain, system libraries, build scripts — pinned by git commit and content hash. Full reproducibility is not the status quo; often there are instance-dependent parts of the build process, creating subtle deviations. A common alternative for verifying build provenance is to use a trusted builder such as GitHub Actions to handle build security and create an artifact attestation. Like software correctness, build reproducibility isn’t unique to AI governance, but model inference’s tendency to be complex and closed source could make this requirement especially difficult to achieve.
Hardware Auditability
The credibility of the hardware attestation rests on the assumption that the vendors' TEE implementations (hardware isolation, memory encryption, quoting enclave) are correct. But the design, supply chain, and manufacturing processes of chips are all opaque to end users, which means trust is typically unavoidable. In a governance scenario, an auditor might have access to vendors' manufacturing processes, but that only transfers the trust requirement to the auditor.
Hardware is a very long way from being as auditable as open source, reproducibly-built software, but has progressed further than one might realize. There are a number of established projects producing open silicon designs (see OpenTitan, Caliptra, Tropic Square), some of which have been added to commercial products (see Chromebooks). Security-critical components shared between mutually untrusting parties have a tendency to become public goods (cryptographic primitives, internet infrastructure, OS kernels).
Fabrication and supply chain are still quite opaque, but open designs combined with verifiable implementation correctness go a long way in making chips more verifiable. Demand for auditability can slowly bring transparency to each layer. This Project Sovereign writeup does a good job of concretizing what secure and verifiable hardware would look like and steps to get there.
Hardware Key Provenance
The most difficult-to-accept part of TEE hardware is key provenance; the Root of Trust (RoT) is a small number of hardware vendors (i.e. AMD, Intel, NVIDIA’s Certificate Authorities) that generated and fused the keys onto the chip. Whoever has access to the hardware’s key or is able to certify one can, in principle, produce valid attestation reports for arbitrary measurements without possessing the physical chip. As such, the trust in hardware manufacturers to produce and custody authorization keys is as load-bearing as anything else.
Additional defenses can be layered to make fraudulent attestations more evident, and trust could be dispersed across multiple parties by involving more keys. Ultimately, key provenance requires trust unless we use a method like Physically Unclonable Functions to bind cryptographic identities to chips.
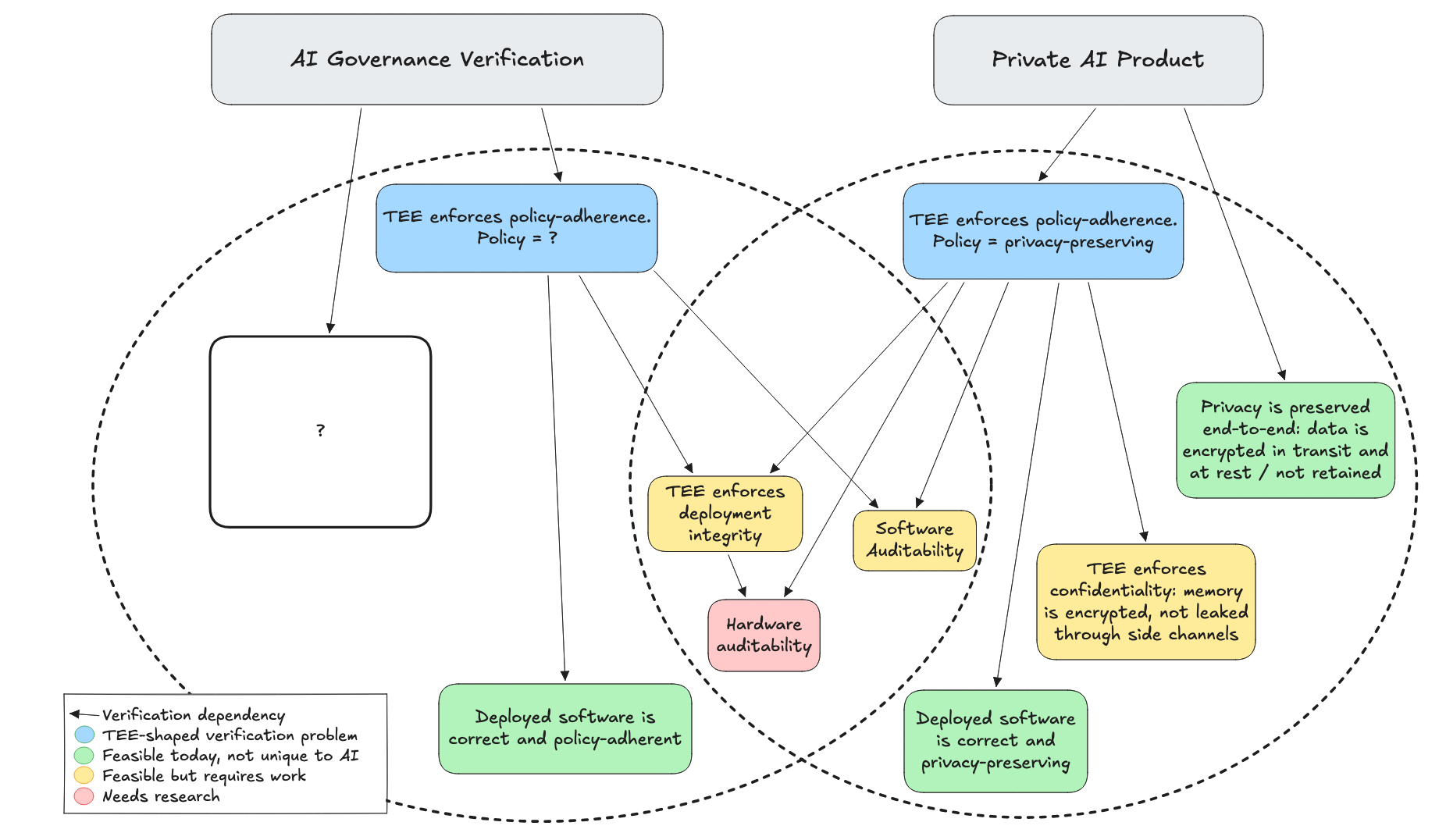
The shared requirements already present considerable challenges… but we also skipped a few steps in between.
Bridging the gap
Our goal is to bootstrap verification for governance purposes (treaties, agreements, regulations) from verification for users interacting with AI products. Given a TEE that enforces policy-adherent inference, what problems are remaining?
An auditor who verifies a CVM's attestation report can verify properties of that deployment, but the machine’s hypervisor could just spin up a second CVM that uses a different model or bypasses all monitoring. These CVMs cannot access information about each other; they are isolated TEEs.

The difference between a deployment-level attestation and chip-wide monitoring is the gaping hole in this plan. It means we could verify attestations and declarations that make it seem like every GPU is completely occupied with compliant workloads, but actually 1% of the computational resources are used elsewhere. If a datacenter has 10,000 GPUs that each do 10^15 FLOPs/second, 1% reaches the MIRI treaty’s 10^24 “strict threshold” in about 100 days. This calculation is very “back of the envelope” rough, but our margin for error is pretty narrow.
Resource Accounting
The auditor needs reassurance that all activity is accounted for in the attestations and reports. Compute accounting is frequently mentioned in international treaty verification literature, probably because computational resources are a good proxy for capabilities and are attached to silicon chips produced by a centralized group of vendors.
On-chip measurements could perhaps provide granular monitoring of LLM activity through integrated hardware components or existing performance counters from which inference activity can be extrapolated. On-chip methods could even directly limit the quantity of computations a chip is licensed to do. At the same time, performance counters have also been considered a source of side-channel attacks affecting TEE privacy due to how much they reveal about low-level operations. There are also TEE-based resource accounting techniques.
Data center telemetry through power draw monitoring and network metering could help corroborate or detect discrepancies between declared workloads and data center-wide activity. Training and inference, for example, have distinct patterns in network traffic and power draw fingerprints. These signals are hopefully similarly privacy-preserving, though I’m not sure how granular they can be.
Random challenges can make cheating harder, as an operator would need to maintain a consistent false accounting across all signals simultaneously. For example, memory residency challenges can help detect unreported workloads or model-swapping. For example, one way to probe whether a claimed piece of data (i.e. a set of model weights) resides in a GPU’s high bandwidth memory (HBM) by requiring a low-latency computation with it. A GPU that doesn’t actually have the data loaded in HBM would not be able to return a result in time. There could be a wide range of available techniques to probe resource usage or fingerprint models, which we should evaluate wrt privacy.
Recomputation can help detect overstated resource usage: an auditor may randomly select workloads and reproduce their computation declarations, perhaps through a mirrored CVM setup that keeps the data and model private. One technique for verification of data centers is to simply run challenged workloads in CVMs. The auditor verifies a stream of workload declarations, all (encrypted) traffic flows through a gateway, and the auditor randomly selects packets to be audited. A prover then demonstrates inclusion of the packet in previous commitments (e.g. a Merkle tree inclusion proof) and the declaration’s accuracy through recomputation.
Practical Considerations
Research into TEE-based verification protocols illustrated promising verification techniques using a small model within the CPU enclave, but still need to be tested with frontier models and in production environments. Most production inference engines are optimized for performance rather than verifiability, so there’s going to be a privacy premium. While it was exciting to be able to point to TEE-based Private AI products (not just theoretical verification schemes) there are still unanswered questions.
A big question for auditability is: can model weights, architecture, and other proprietary parts of the stack remain private without undermining auditability? Perhaps yes: if we think of the model and the user input as operands to arithmetic operations, keeping them private doesn’t really hurt. Perhaps no: inference is certainly much more complex than this post gives it credit for, and reasoning about software correctness may prove too difficult with an incomplete view of it.
Another challenge is adaptation to the more severe threat model in which actors have qualitatively different relationships with each other. In some cases, they may be the same entity or more likely to collude. The adversary in Confidential Computing is a dishonest operator or service provider who wants to cut corners commercially. The adversary in an international treaty scenario is a nation-state who wants to covertly train intelligent models and potentially has advance physical access to data centers, leverage over hardware vendors, enormous capacity for intelligence operations, etc.
A company needs to solve auditability challenges in order to produce a Verifiably Confidential AI service, but the marginal benefit to a company in making it robust to extreme adversaries is low. Process friction is often how software updates become neglected, key revocation ignored, hash computations substituted with empty signature checks, etc. If I were an adversary, I would probably first search for low-hanging fruit stemming from verification complacency.
The Hardest Problems
The gap is considerable. Do we have any hope of closing it? Let’s take stock of the problems that seem the most challenging and determine what makes them hard.
Hard, but with known solutions: Most of the problems are not unique to AI or TEEs at all; software bugs and stale versions/proofs give us plenty of challenges. Deployment integrity can be undermined by kernel vulnerabilities, non-targetability in routing, metadata leakage, and simply neglecting to include something in the measurement. TEE security doesn’t have a great reputation now but it is possible to build confidence through years of red-teaming, especially if the industry moves further towards transparency; physical and side-channel attacks don’t have to be the bottomless pit they seem to be right now. The most natural approach to these problems is to continuously discover and fix the lowest-hanging fruit.
Hard, but requires buy-in and effort: some problems also clearly have solutions, but require substantial effort and will to execute: fully reproducible builds, open silicon designs, designs trading performance for security, more transparent software and hardware supply chains. I was personally pessimistic about open silicon designs until seeing companies pursuing and supporting projects like OpenTitan, Caliptra, Tropic Square, Project Sovereign. As the world more strongly emphasizes hardware as a shared trusted component of security-critical systems – like open source infrastructure software – it may follow a similar path towards auditable supply chains.
Hard, with no settled design: a last set of problems doesn't yet have a solution. It seems extremely difficult to verify the completeness of workload declarations and form a tight-enough bound on unknown compute; resource accounting for even a known data center seems difficult. But we might be able to piece together enough information through facility telemetry, random challenges, recomputation, spot checking workloads, etc., without invasive monitoring. The biggest question for me is Root of Trust in hardware vendors to generate and/or certify chip keys.
Conclusion: are TEEs a valid solution?
One of the most concerning trajectories for AI is mass surveillance excused as a “freedom tax” paid to enforce AI safety. Many companies have created privacy-preserving AI products using CVMs and creating an end-to-end encrypted channel between the user’s chat app and inference server.
Governability should not be a reason to shoot down these products. Despite the opacity of encryption, the CVM inference system actually has the potential to be more auditable, not less, and facilitate meaningful safety-related monitoring without mass surveillance. Market demand for these products helps push companies to solve security and auditability challenges that could be reused for governance-related verification.
My main takeaways:
- Inference in CVMs has commercial value: Deployment integrity and privacy for both user and tenant are attractive commercial use cases in AI, directly supported by pretty much all of the hardware vendors you can think of. Due to vast demand (in the past and future), they have matured rapidly since the last time you thought about TEEs.
- We can have both privacy and auditability: Focusing on the way data is handled rather than the data itself is privacy-preserving and helps decompose the verification problem. Require that the software follow a policy of access control, audit logging, and safety-related monitoring as part of the process (AI also makes this easier); require hardware to attest to running this exact software. The auditor’s job is to check deployment integrity on the hardware, the software’s correctness and policy-adherence, and that all computational resources are accounted for.
- There are significant steps to map from cloud computing use case to governance: the primary problem solved by TEEs is deployment integrity; software auditability is an additional requirement when the user/auditor didn’t write the code. The governance verification problem – which involves bounding the amount of unaccounted computational resources – also goes beyond the verification of one deployed CVM. A root of trust in the hardware vendor is a major sore point worth addressing.
- We should lean into commercial demand for auditability: Existing commercial uses of CVMs for verifiably private AI products and Confidential Computing motivate companies to work on the auditability problems and security issues. Hardware support seems quite widespread, including in the accelerator chips used for AI. It is hugely beneficial to invest in developing these kinds of products.
- Security issues are numerous and fixable: In our threat model, deployment integrity and confidentiality are unacceptably vulnerable to a wide range of TEE side-channel attacks, physical attacks, and bugs in security-critical components of the software. These issues represent the scope and intensity of the problem; I wouldn’t say they present a fundamental limitation. AI’s immense cybercapabilities both raise the bar and accelerate how quickly we can work through these problems.
- Open hardware is the way: Verifiability of components critical to security is a forcing function for transparency. Universally-trusted cryptographic primitives, the Linux kernel, and internet trust infrastructure are open source so they can be verified by the wide range of mutually-distrusting parties that share a dependence on them. Hardware needs to follow a similar path if we are to use it in international governance scenarios. And it seems to be doing so.
Given their enormous potential upsides, I’d encourage more optimism in hardware verification, open silicon designs, and putting LLMs in TEEs. The problems are numerous and challenging… so we should work on them.